MPI implementations of dipolar/demagnetized fields computing package contains MPI implementations of dipolar/demagnetized fields computing package
MPI implementations of dipolar/demagnetized fields computing package contains MPI implementations of dipolar/demagnetized fields computing package
The MPI parallelization of the demagnetized operator is not sotrivial because the demagnetized field needs to the the mass center and the magnetization at all macro cells of its neighbor cores. The macro cells network is composed by a grid of macro cells m. The mass center \(X^m\) of the macro cell \(m\) is the magnetic barycenter of the position of particles in the macro cell m whose weight is the magnetic moments. The magnetization field \(M^m\) applied on the mass center of the macro cell is the sum of magnetic moment of spins included in the macro cell
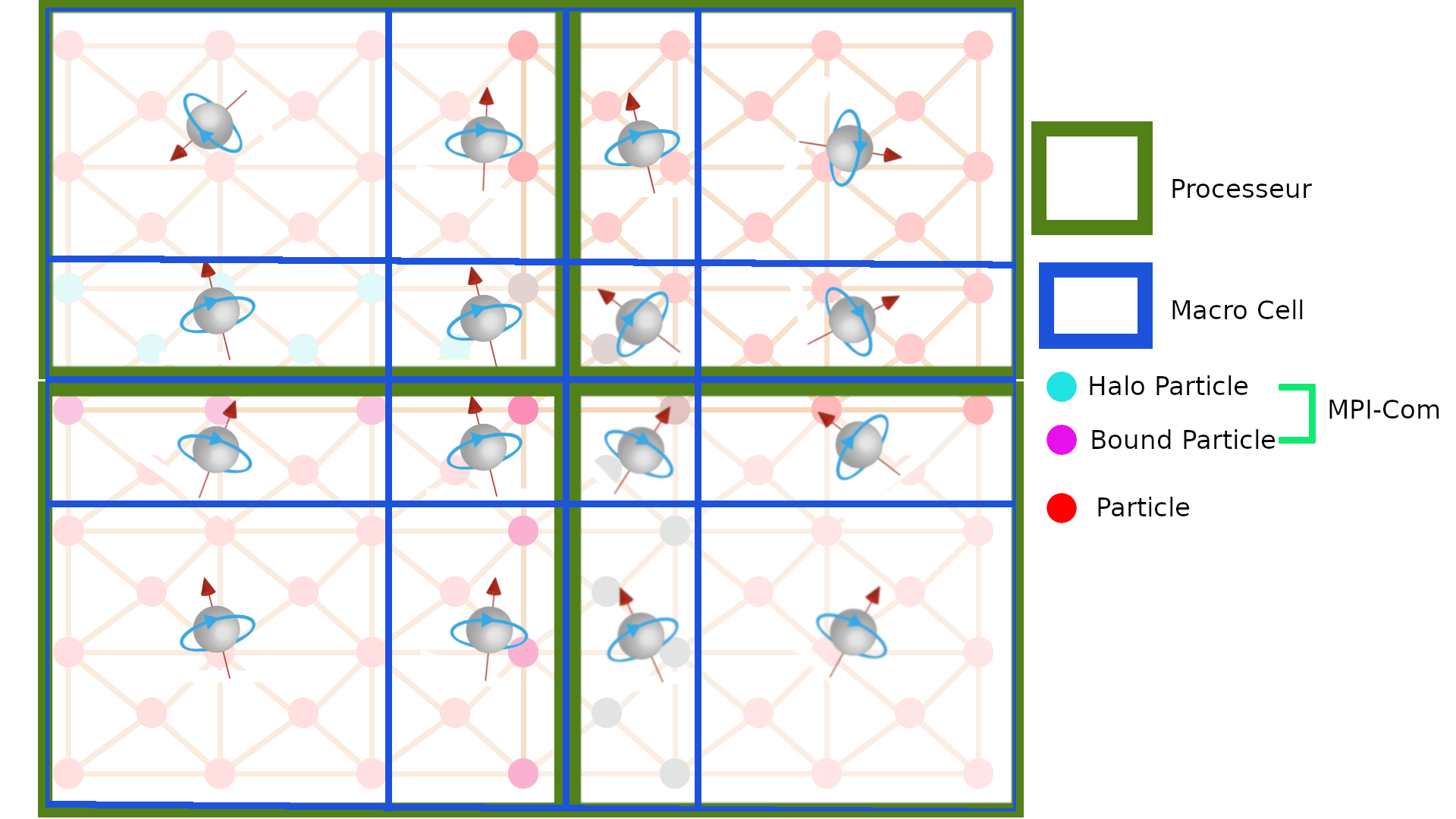 |
| macro cells |
3 strategies are used to solve the problem:
- All-Master : each core owns the macro cells data ( \(X^m,M^m,H_{dem}^m\)) over the whole macro cells grid. Each core computes the demagnetized field \(H_{dem}\) within a slice of the macro cell grid. Then, each core gathers \(H_{dem}\) from the slices of the all other cores.
- One-Master : each core \(c\) owns the macro cell data only on the macro cells which contain a particle of the network of the core \(c\). A master core gathers the macro cell data by a variable sum reduction over the other cores in order to compute \(H_{dem}\) on the whole macro cells grid. Finaly, the master core scatters the demagnetized field to all other cores.
- No-Master: each core has its own macro cells grid which are not shared with other cores. Each core sends to other core its macro cell data to compute the demagnetized field on the macro cells within its own macro cells grid. In this case, the macro cell size is not uniform over the macro cells network.
all master cores communication
Each core c computes its own contribution into the macro cells network data of size \(N^{mc}\):
- \(N^m\) of size \(N^{mc}\), is number of particles in macro cell m
- \(X^m\) of size \(3 \times N^{mc}\) : sum of the particles position in macro cell m
- \(M^m\) of size \(3 \times N^{mc}\) : sum of the particles magnetic moment in macro cell m
The total number of particles in macro cell \(m\) is the sum of the particles number of the network of cores computed by mpi-sum-all-reduction over a fixed size array.
The mass center \(C^m=\frac{X^m}{N^m}\) of each macro cell \(m\) is the mean sum of position of particles of the network of cores. It is another mpi-sum-all-reduction over a fixed size array.
The magnetization field of a macro cell \(m\) is the sum of the magnetic dierction of particles of the network of cores. It is another mpi-sum-all-reduction over a fixed size array.
Each core computes the demagnetized field over a slice of the macro cells grid and gathers all the slices from the other cores of the demagnetized field into the \(H_{dem}\) field defined on the whole macro cells grid.
This method ensures that the macro cell size is constant.
\( (N^m,X^m,M^m) \rightarrow{\text{All Reduce}} (N^m,X^m,M^m) \rightarrow[\text{in core c}]{\text{compute}} H^m_{dem}(C^m,M^m)[C^{m \in slice_c}] \rightarrow{\text{All Gather}} H^m_{dem} \)
This implemntation is devoted to the classes:
- SMOMPI_AllMasterMacroCellsNetwork for creating the macro cells network data
- SMOMPI_AllMasterMacroCellsMagnetizationField for computing magnetization field on the macro cells network
- SMOMPI_AllMasterMacroCellsDemagnetizedField for computing edmagnetized field on the macro cells network
one master core communication
Each core c computes the macro cells network data whose macro cell owns at last on particle of the network of the core. The number of macro cells of the core c is \(N^{mc}_c\)
- \(N_c^m\) of size \(N^c_{mc}\), is number of particles in network of core \(c\) and in macro cell m
- \(X_c^m\) of size \(3 \times N^c_{mc}\) : sum of position of the particles of core \(c\) in macro cell m
- \(M_c^m\): sum of the magnetic moment of particles in core \(c\) and in macro cell m
- \(I_c : [0,N^{mc}_c[ \mapsto [0,N^{mc}[\) is the map from the index of macro cell in the macro cells network of core c to its corresponding index in the whole macro cells network.
- \(H_{dem,c}^m\) of size \(3 \times N_{mc}^c\) : demagnetized field on macro cells into the core c.
Each core c sends \((I_c,N_c,X_c,M_c)\) to a master core \(c_m\) to gather the macro cells network data \((N^m,X^m,M^m)\) of the whole macro cells network within by master core \(c_m\) in order to build \(C^m=\frac{X^m}{N^m}\). The demagnetized field \(H_{dem}(C^m)\) is computed and scattered to all other cores into \(H_{dem,c}^m\)
\[ (I^m,N^m,X^m,M^m)_c \rightarrow[\text{to core $c_m$}]{\text{Gather}} (N^m,X^m,M^m) \rightarrow[\text{in core $c_m$}]{\text{compute}} H^m_{dem}(\frac{X^m}{N^m},M^m) \rightarrow[\text{to core c}]{\text{scatter}} H^m_{dem,c} \]
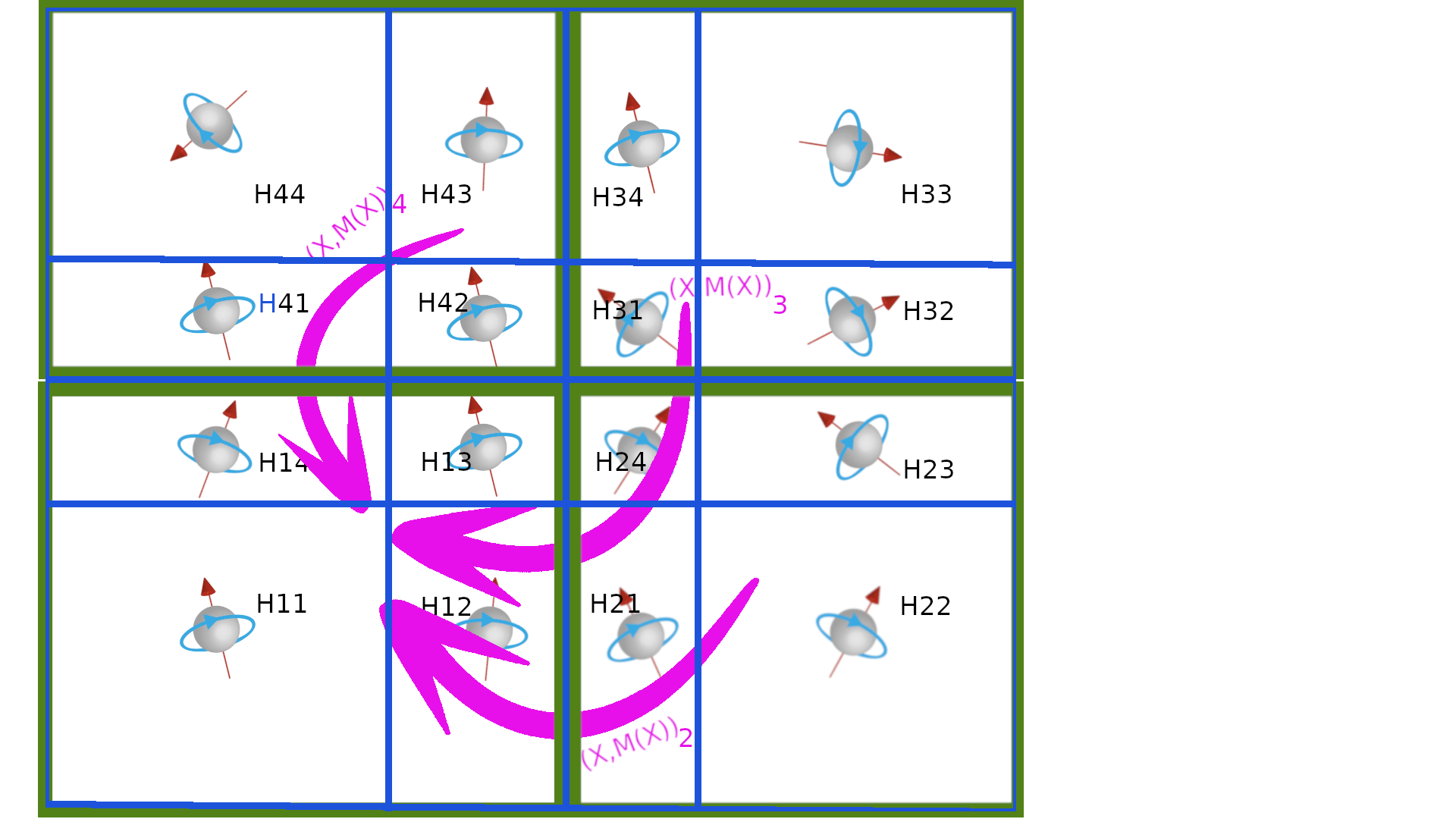 |
 |
| receive | send |
This implemntation is devoted to the classes:
- SMOMPI_OneMasterMasterMacroCellsNetwork for creating the macro cells network data
- SMOMPI_OneMasterMacroCellsMagnetizationField for computing magnetization field on the macro cells network
- SMOMPI_OneMasterMacroCellsDemagnetizedField for computing edmagnetized field on the macro cells network
no master communication
Each core c computes its own macro cells grid. The number of macro cells of the grid of the core c is \(N^{mc}_c\)
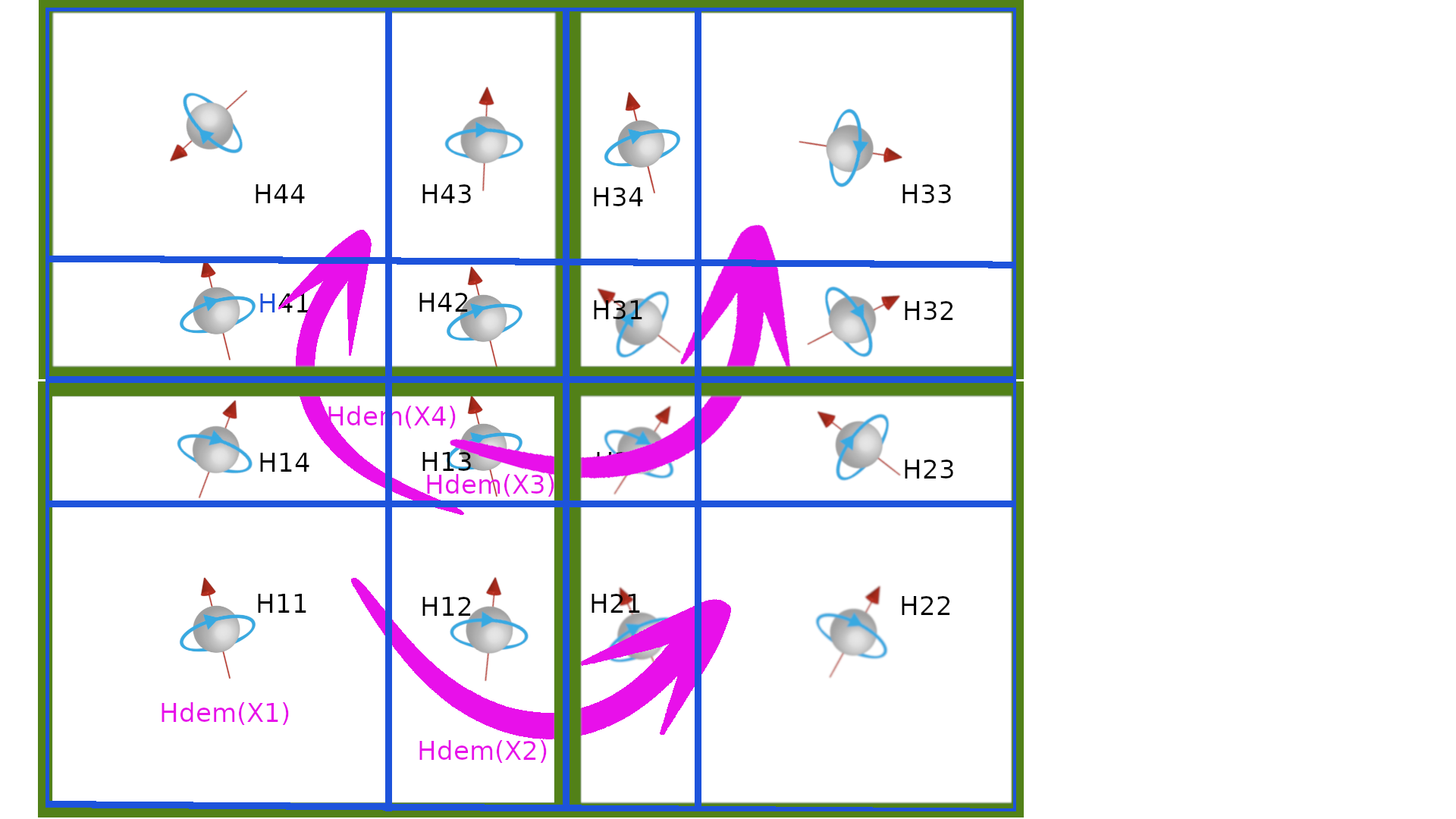
Each core \(c_i\) receives \((C,M)_j\) from all other cores \(c_j\). When the data are received, the demagnetized field from macro cells on \(c_j\) is computed \(H_{cdem,_i}(C_i)+=H^{dem}_{(C_j,M_j)}(C_i)\). The cpu time for communication is supposed to be compensated by the computation time.
\( (C,M)_i \rightarrow[\text{from core $c_j$}]{\text{receive}} (C,M)_j \rightarrow[\text{in core c_i}]{\text{compute}} H_{dem}(C_j,M_j)[C_i] \)
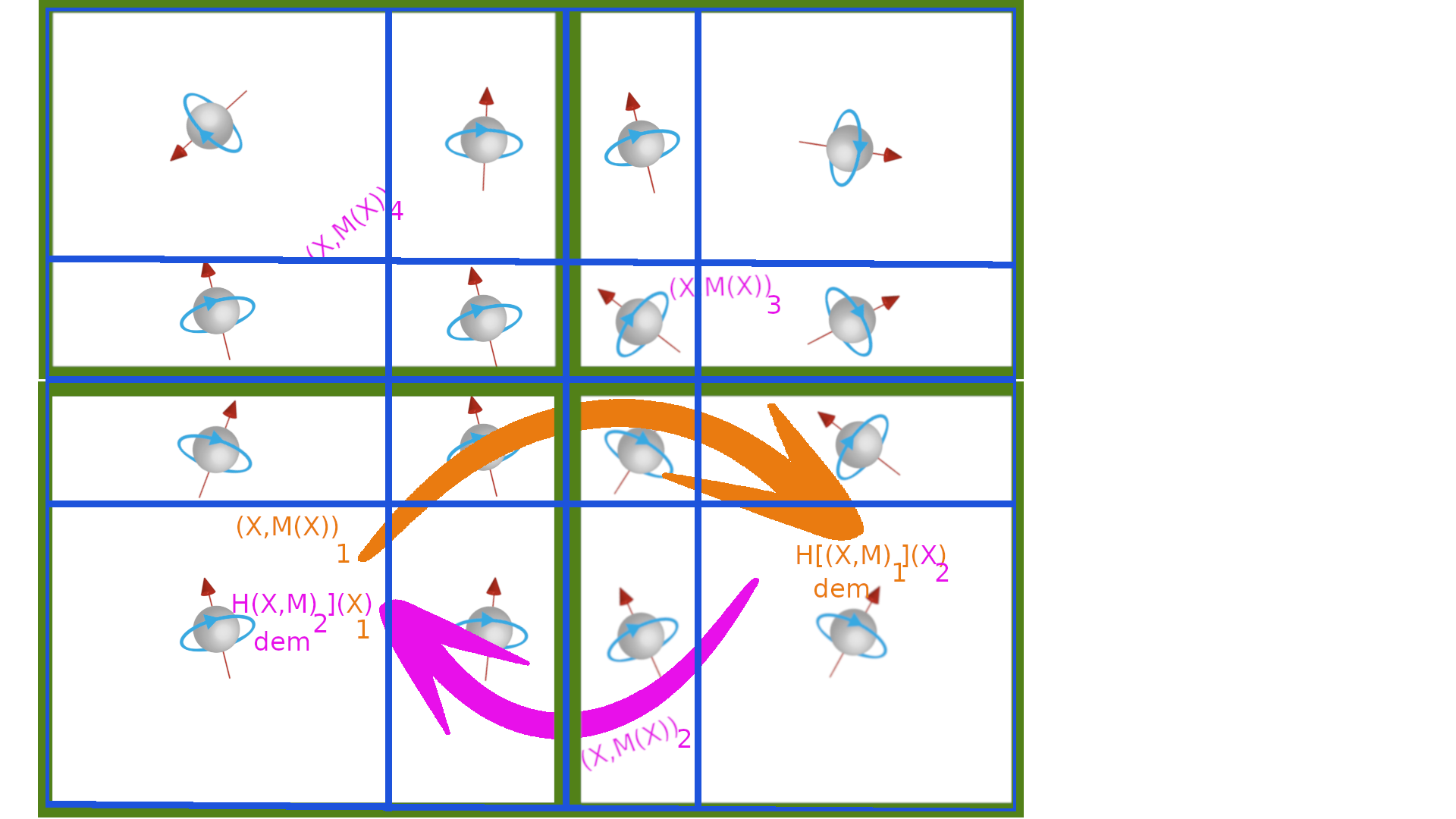 |
| receive and compute |
This implemntation is devoted to the classes:
- SMOMPI_NoMasterMasterMacroCellsNetwork for creating the macro cells network data
- SMOMPI_NoMasterMacroCellsMagnetizationField for computing magnetization field on the macro cells network
- SMOMPI_NoMasterMacroCellsDemagnetizedField for computing edmagnetized field on the macro cells network
In that case the size of macro cells is not necessarly uniform.
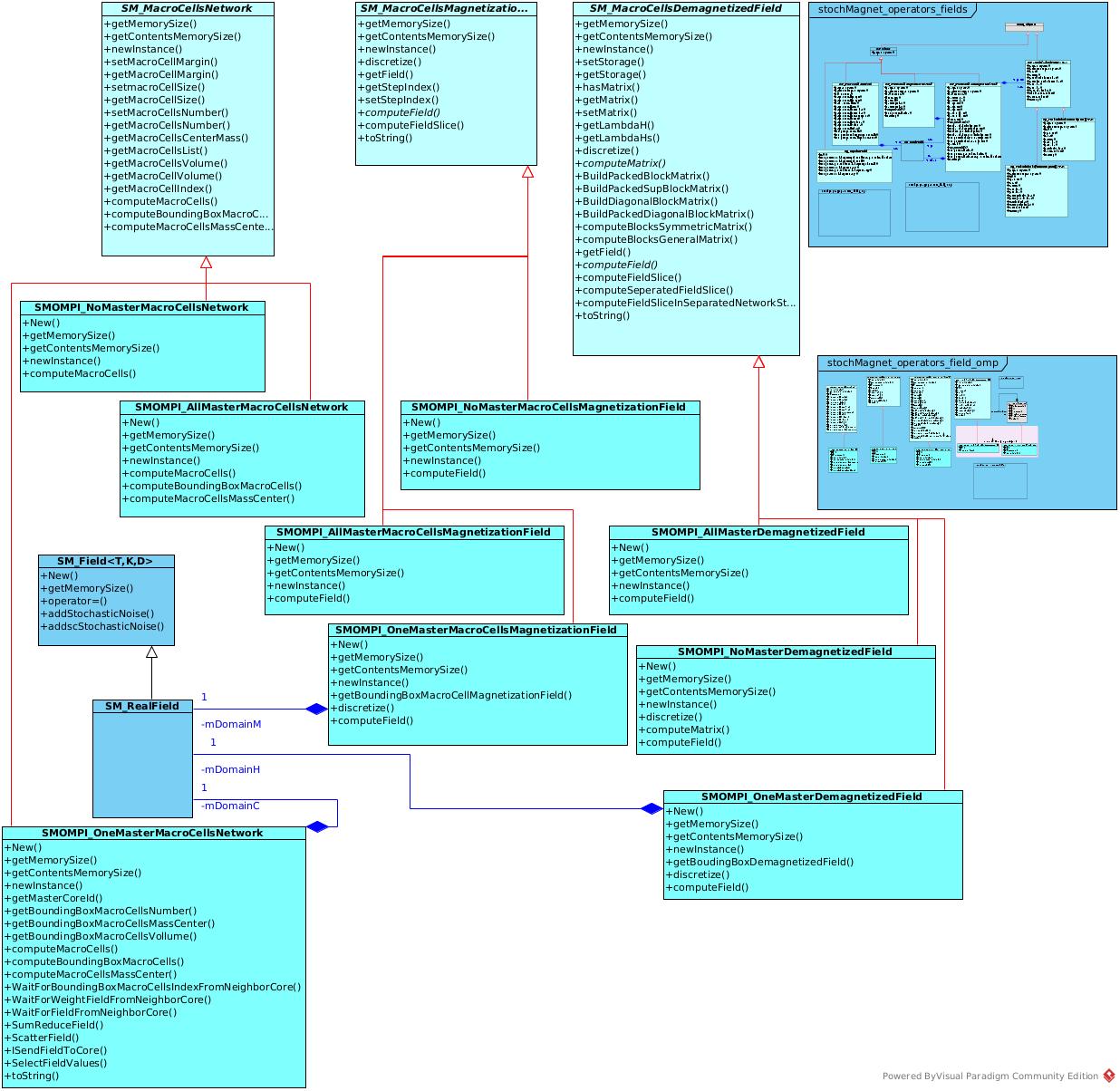
The UML organization of the package