Se ha seleccionado un modelo
probabilista, que hace que los datos observados sean realizaciones
de variables aleatorias. Denotemos por
![]() los
datos y por
los
datos y por
![]() las variables aleatorias que los
modelan. Sobre la ley de estas variables aleatorias se plantean
un cierto número de hipótesis que no se pondrán en duda. Una
hipótesis
en particular,
las variables aleatorias que los
modelan. Sobre la ley de estas variables aleatorias se plantean
un cierto número de hipótesis que no se pondrán en duda. Una
hipótesis
en particular,
![]() , será sometida a test.
La decisión dependerá del valor que tome una cierta función
de los datos que llamaremos
, será sometida a test.
La decisión dependerá del valor que tome una cierta función
de los datos que llamaremos ![]() :
:
En el modelo, ![]() es una variable aleatoria, el
estadígrafo del test.
Se selecciona de manera tal que su ley
de probabilidad bajo la hipótesis
es una variable aleatoria, el
estadígrafo del test.
Se selecciona de manera tal que su ley
de probabilidad bajo la hipótesis
![]() es conocida.
Denotamos esta ley por
es conocida.
Denotamos esta ley por ![]() . Si los
. Si los ![]() son realizaciones de
las
son realizaciones de
las ![]() , entonces
, entonces
![]() es el valor que toma
es el valor que toma
![]() . El test consiste en rechazar la hipótesis
. El test consiste en rechazar la hipótesis
![]() cuando el valor de
cuando el valor de ![]() es muy poco verosímil para
es muy poco verosímil para ![]() .
.
Para la ley de probabilidad ![]() , los valores más plausibles
están contenidos dentro de sus
intervalos
de
dispersión. Estos se
expresan con la ayuda de la
función cuantil.
Si
, los valores más plausibles
están contenidos dentro de sus
intervalos
de
dispersión. Estos se
expresan con la ayuda de la
función cuantil.
Si ![]() es una variable aleatoria, la
función cuantil de la ley de
es una variable aleatoria, la
función cuantil de la ley de ![]() es la función que va de
es la función que va de
![]() en
en
![]() , y que a cada
, y que a cada
![]() asocia el valor:
asocia el valor:
Es la inversa de la función de distribución. Las funciones cuantiles más usadas, tal y como lo están las funciones de distribución de las leyes usuales, están programadas en la mayoría de los sistemas de cálculo.
Definición 1.3
Sea ![]() une variable aleatoria y
une variable aleatoria y ![]() un
número real entre 0 y
un
número real entre 0 y ![]() . Llamamos
intervalo
de dispersión de nivel
. Llamamos
intervalo
de dispersión de nivel
![]() a todo intervalo de la
forma:
a todo intervalo de la
forma:
En estadística emplear números reales ![]() entre 0 y
entre 0 y ![]() constituye una tradición. La misma tradición hace que se les
asigne prioritariamente los valores
constituye una tradición. La misma tradición hace que se les
asigne prioritariamente los valores ![]() y
y ![]() , menos
frecuentemente
, menos
frecuentemente ![]() ,
, ![]() ó
ó ![]() . Por tanto debemos leer
. Por tanto debemos leer
![]() como ''una proporción débil'', y
como ''una proporción débil'', y
![]() como ''una
proporción fuerte''. Un intervalo de dispersión de nivel
como ''una
proporción fuerte''. Un intervalo de dispersión de nivel
![]() para
para ![]() es uno tal que
es uno tal que ![]() pertenece a ese
intervalo con probabilidad
pertenece a ese
intervalo con probabilidad
![]() . El contiene, por tanto,
a una fuerte proporción de los valores que tomará
. El contiene, por tanto,
a una fuerte proporción de los valores que tomará ![]() aún
cuando el sea mucho más pequeño que el soporte de la ley.
Según los valores de
aún
cuando el sea mucho más pequeño que el soporte de la ley.
Según los valores de ![]() , decimos que un intervalo de
dispersión de nivel
, decimos que un intervalo de
dispersión de nivel
![]() es:
es:
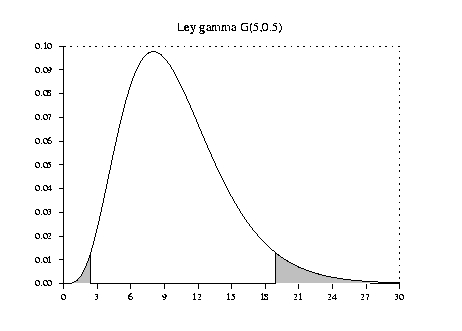
Presentamos los intervalos de dispersión unilaterales y
simétricos, de nivel ![]() y
y ![]() para la
ley normal
para la
ley normal
![]() .
.
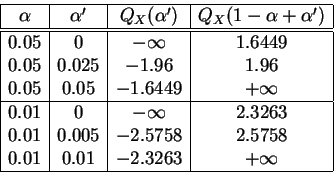
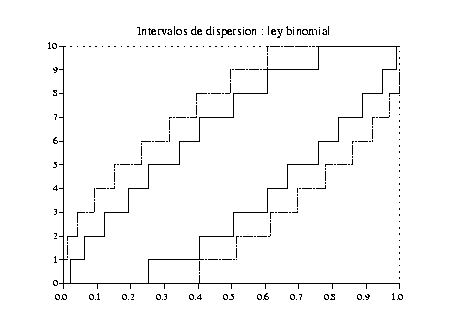
Cuando la ley de la variable aleatoria ![]() es discreta, la
noción de intervalo de dispersión puede contener alguna
ambigüedad. Consideremos, por ejemplo, la
ley
binomial
es discreta, la
noción de intervalo de dispersión puede contener alguna
ambigüedad. Consideremos, por ejemplo, la
ley
binomial
![]() . Veamos los valores de su función de distribución.
. Veamos los valores de su función de distribución.
Fijemos
![]() . En todo rigor, el valor de la
función cuantil en el punto
. En todo rigor, el valor de la
función cuantil en el punto ![]() es
es ![]() . El intervalo
. El intervalo ![]() debería ser por tanto un intervalo de dispersión de nivel
debería ser por tanto un intervalo de dispersión de nivel
![]() para la ley
para la ley
![]() . Sin embargo su probabilidad
es de
. Sin embargo su probabilidad
es de ![]() . Para los cálculos que emplean intervalos de
dispersión, siempre se aplica un principio de precaución, el
cual consiste en garantizar el nivel. Por tanto
consideraremos como intervalos de dispersión de nivel
. Para los cálculos que emplean intervalos de
dispersión, siempre se aplica un principio de precaución, el
cual consiste en garantizar el nivel. Por tanto
consideraremos como intervalos de dispersión de nivel
![]() sólo a aquellos cuya probabilidad es mayor o
igual a
sólo a aquellos cuya probabilidad es mayor o
igual a
![]() . Este principio lleva a modificar la
definición 1.3 para las leyes discretas que toman
valores en
. Este principio lleva a modificar la
definición 1.3 para las leyes discretas que toman
valores en
![]() , reemplazando el borde derecho
, reemplazando el borde derecho
![]() , por
, por
![]() . La tabla
que mostramos a continuación nos da una lista de intervalos de
dispersión de nivel
. La tabla
que mostramos a continuación nos da una lista de intervalos de
dispersión de nivel ![]() , conjuntamente con su
probabilidad exacta, para la ley
, conjuntamente con su
probabilidad exacta, para la ley
![]() .
.
Dos de los intervalos tienen amplitud mínima, ![]() y
y ![]() .
Seleccionaremos a aquél que tiene la mayor probabilidad, es
decir a
.
Seleccionaremos a aquél que tiene la mayor probabilidad, es
decir a ![]() . La figura 2 representa en función de
. La figura 2 representa en función de
![]() los intervalos de dispersión optimales, en el sentido que
hemos definido anteriormente, para la ley binomial
los intervalos de dispersión optimales, en el sentido que
hemos definido anteriormente, para la ley binomial
![]() , así como los intervalos de dispersión simétricos.
, así como los intervalos de dispersión simétricos.
Hacer un test consiste en rechazar la
hipótesis
![]() si el valor que toma el estadígrafo del
test cae fuera del intervalo de dispersión del nivel
dado.
si el valor que toma el estadígrafo del
test cae fuera del intervalo de dispersión del nivel
dado.
Proposición 1.4
Sea
![]() una hipótesis y
una hipótesis y ![]() un
número real entre 0 y
un
número real entre 0 y ![]() . Se define un test de umbral
. Se define un test de umbral
![]() o test de nivel
o test de nivel ![]() para
para
![]() por la
regla de decisión:
por la
regla de decisión:
Hasta ahora hemos dejado una gran flexibilidad para seleccionar el intervalo de dispersión. Los intervalos más usados son simétricos o unilaterales.
Definición 1.5 Se dice que un test es:
En el caso de la eficiencia de un medicamento, con el número de
enfermos curados como estadígrafo del test, seleccionaremos un
test unilateral (el tratamiento es ineficaz si la frecuencia de
curados es muy débil, y es eficaz si la frecuencia es lo
suficientemente grande). Para probar un generador
pseudo-aleatorio, con el número de resultados entre ![]() y
y
![]() como estadígrafo del test, rechazaremos tanto los valores
muy grandes como los muy pequeños y el test será bilateral.
como estadígrafo del test, rechazaremos tanto los valores
muy grandes como los muy pequeños y el test será bilateral.
En la definición que damos a continuación resumimos los tres tipos de test usuales.
Definición 1.6
Sean
![]() la
hipótesis nula,
la
hipótesis nula, ![]() el
umbral,
el
umbral, ![]() el
estadígrafo del test y
el
estadígrafo del test y ![]() su función cuantil bajo la
hipótesis
su función cuantil bajo la
hipótesis
![]() .
.
Supongamos que el estadígrafo de test ![]() sigue, bajo la
hipótesis
sigue, bajo la
hipótesis
![]() , la
ley binomial
, la
ley binomial
![]() ,
igual que en el ejemplo del generador pseudo-aleatorio. El
intervalo de dispersión simétrico de nivel
,
igual que en el ejemplo del generador pseudo-aleatorio. El
intervalo de dispersión simétrico de nivel
![]() es
es
![]() . El test bilateral de umbral
. El test bilateral de umbral ![]() consistirá en
rechazar
consistirá en
rechazar
![]() si el estadígrafo de test toma valores
inferiores a
si el estadígrafo de test toma valores
inferiores a ![]() o superiores a
o superiores a ![]() . Para la ley binomial, como
para otras leyes, podemos decidir de utilizar la aproximación
por la
ley normal: si
. Para la ley binomial, como
para otras leyes, podemos decidir de utilizar la aproximación
por la
ley normal: si ![]() es lo suficientemente grande, la ley
es lo suficientemente grande, la ley
![]() está cerca de la ley normal que tiene la misma
esperanza y
la misma
varianza que ella. En este caso la ley de
está cerca de la ley normal que tiene la misma
esperanza y
la misma
varianza que ella. En este caso la ley de ![]() está cerca de la ley
está cerca de la ley
![]() . El intervalo de
dispersión simétrico de nivel
. El intervalo de
dispersión simétrico de nivel ![]() para esta ley es
para esta ley es
![]() . Según este intervalo, deberíamos rechazar
también los valores
. Según este intervalo, deberíamos rechazar
también los valores ![]() y
y ![]() . Este tipo de aproximación era
muy corriente hacerla cuando solamente se disponía de tablas de
cuantiles.
Ya en la actualidad los sistemas de cálculo que
existen son capaces de calcular en forma precisa cualquier cuantil
de las leyes usuales. Como regla general debe evitarse emplear un
resultado de aproximación cuando se puede calcular exactamente.
Los cuantiles de la ley
. Este tipo de aproximación era
muy corriente hacerla cuando solamente se disponía de tablas de
cuantiles.
Ya en la actualidad los sistemas de cálculo que
existen son capaces de calcular en forma precisa cualquier cuantil
de las leyes usuales. Como regla general debe evitarse emplear un
resultado de aproximación cuando se puede calcular exactamente.
Los cuantiles de la ley
![]() nunca estuvieron en las
tablas. Para calcularlos, se empleaban los de la ley
nunca estuvieron en las
tablas. Para calcularlos, se empleaban los de la ley
![]() , reemplazando al estadígrafo de test
, reemplazando al estadígrafo de test ![]() por su valor
centrado y reducido:
por su valor
centrado y reducido:
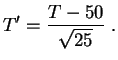
Si admitimos que la variable ![]() sigue la ley
sigue la ley
![]() , el
test bilateral de umbral
, el
test bilateral de umbral ![]() consiste en rechazar todo valor
que se encuentre fuera del intervalo de dispersión
consiste en rechazar todo valor
que se encuentre fuera del intervalo de dispersión
![]() . Esto es, evidentemente, equivalente a
rechazar los valores de
. Esto es, evidentemente, equivalente a
rechazar los valores de ![]() que se encuentren fuera del intervalo
que se encuentren fuera del intervalo
![]() . Hay otras transformaciones posibles. Si
. Hay otras transformaciones posibles. Si ![]() sigue la ley
sigue la ley
![]() , entonces
, entonces
![]() sigue la
ley
chi-cuadrado
sigue la
ley
chi-cuadrado
![]() . Rechazar
los valores de
. Rechazar
los valores de ![]() que se encuentran fuera del intervalo
que se encuentran fuera del intervalo
![]() es equivalente a rechazar los valores de
es equivalente a rechazar los valores de
![]() mayores que
mayores que
![]() , que es efectivamente el
cuantil de orden
, que es efectivamente el
cuantil de orden ![]() de la ley
de la ley
![]() . Notemos que un
test bilateral sobre el estadígrafo
. Notemos que un
test bilateral sobre el estadígrafo ![]() es equivalente a un
test unilateral a la derecha sobre el estadígrafo
es equivalente a un
test unilateral a la derecha sobre el estadígrafo ![]() .
.
Los capítulos 2 y
3 contienen los ejemplos más clásicos
de tests, primero con los cuantiles y después en el marco
gaussiano. No siempre precisaremos si se trata de tests
bilaterales o unilaterales. Lo importante es describir la
hipótesis
![]() , el estadígrafo de test
, el estadígrafo de test ![]() y su ley
bajo
y su ley
bajo
![]() . Decidir si el test debe ser unilateral a la
izquierda, unilateral a la derecha o bilateral es muy
frecuentemente un problema de sentido común.
. Decidir si el test debe ser unilateral a la
izquierda, unilateral a la derecha o bilateral es muy
frecuentemente un problema de sentido común.