| Loi | appelation R | Arguments |
| bêta | beta |
forme 1, forme 2 |
| binomiale | binom |
size, prob |
| chi deux | chisq |
df (degrés de liberté) |
| uniforme | unif |
min, max |
| exponentielle | exp |
rate |
| Fisher | f |
df1, df2 |
| gamma | gamma |
forme, echelle |
| géometrique | geom |
prob |
| hypergéometrique | hyper |
m, n, k (taille échantillon) |
| binomiale négative | nbinom |
size, prob |
| normale | norm |
mean, sd |
| Poisson | pois |
lambda |
| Student | t |
df |
| Weibull | weibull |
forme, echelle |
unif
porte par défaut sur l'intervalle norm est centrée réduite par défaut.
Pour effectuer un calcul avec une de ces lois, il suffit
d'utiliser comme fonction
l'une des appellations R ci-dessus avec le préfixe d pour une
densité,
p pour une fonction de répartition, q pour une
fonction quantile
et r pour un tirage aléatoire. Voici quelques exemples :
x <- rnorm(100) # 100 tirages, loi N(0,1) w <- rexp(1000, rate=.1) # 1000 tirages, loi exponentielle dpois(0:2, lambda=4) # probablités de 0,1,2 pour la loi Poisson(4) pnorm(12,mean=10,sd=2) # P(X < 12) pour la loi N(10,4) qnorm(.75,mean=10,sd=2) # 3ème quartile de la loi N(10,4)
Voici à titre d'exemple une utilisation de la génération de nombres
aléatoires pour évaluer une intégrale numérique (Méthode de Monte
Carlo).
Soit ![]() une fonction réelle intégrable sur un intervalle
une fonction réelle intégrable sur un intervalle ![]() .
Nous souhaitons calculer une valeur approchée de
.
Nous souhaitons calculer une valeur approchée de
![]() .
Générons un échantillon
.
Générons un échantillon
![]() de taille
de taille ![]() de loi uniforme sur
de loi uniforme sur ![]() et calculons :
et calculons :
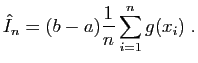
integrate :
u <- runif(1000000, min=0, max=pi/2)
I <- pi/2* mean(sin(u)*exp(-u^2))
f<-function(x){sin(x)*exp(-x^2)}
integrate(f,lower=0,upper=pi/2)
Tracés de densités et de fonctions de répartitions
Des tracés de densités de probabilité ou de fonctions de
répartition de lois diverses peuvent s'obtenir à l'aide de la
function plot().
Ainsi par exemple pour tracer la densité (répartition des masses)
d'une loi binomiale avec ![]() and
and ![]() , reproduite dans la
figure 13,
on exécute dans R :
, reproduite dans la
figure 13,
on exécute dans R :
x <- 0:10
y <- dbinom(x, size=10, prob=.25) # évalue les probas
{plot(x, y, type = "h", lwd = 30,
main = "Densité Binomiale avec \n n
= 10, p = .25", ylab = "p(x)", lend ="square")}
Pour cet exemple, nous avons d'abord créé le vecteur x
contenant
les entiers allant de 0 à 10. Nous avons ensuite calculé les
probabilités
qu'une variable de loi binomiale
![]() prenne chacune de ces
valeurs, par
prenne chacune de ces
valeurs, par dbinom.
Le type de tracé est spécifié avec l'option type=h
(lignes verticales
d'un diagramme en bâtons), épaissies grâce à l'option
lwd=30. L'option
lend ="square" permet de tracer des barres rectangulaires. Nous
avons ensuite
ajouté des légendes.
Pour tracer des densités de lois absolument continues ou des
fonctions de répartitions
de celles-ci, on peut utiliser la fonction curve(). Par
exemple, le tracé de la densité d'une loi Gaussienne
centrée réduite sur l'intervalle ![]() s'obtient avec la
commande
s'obtient avec la
commande
curve(dnorm(x), from = -3, to = 3)
qui réalise la figure 14.
curve(pnorm(x, mean=10, sd=2), from = 4, to = 16) produit
le tracé de la fonction de répartition d'une loi
curve() permet
également de superposer une courbe
sur un autre tracé (dans ce cas il est inutile de spécifier
from et to). Essayons par exemple
de comparer l'histogramme des fréquences des valeurs obtenues par
un tirage de 1000 nombres selon la loi
simu <- rnorm(1000)
{hist(simu, prob=T, breaks="FD",
main="Histogramme de 1000 tirages N(0,1)")}
curve(dnorm(x), add=T)
qui donne la figure 16.
La fonction sample permet d'extraire des échantillons
d'un ensemble fini quelconque, avec ou sans remise (option
replace).
En voici quelques exemples :
sample(1:100, 1) # choisir un nombre entre 1 et 100
sample(1:6, 10, replace = T) # lancer un dé 10 fois
sample(1:6, 10, T, c(.6,.2,.1,.05,.03,.02)) # un dé non équilibré
urn <- c(rep("red",8),rep("blue",4),rep("yellow",3))
sample(urn, 6, replace = F) # tirer 6 boules dans cette urne
Notons enfin que bien d'autres lois de
probabilités moins usuelles
sont disponibles dans des librairies séparées (evd,
gld, stable, normalp,...).
Notions de statistique inférentielleUn des buts de la statistique est d'estimer les caractéristiques
d'une loi de probabilité à partir d'un nombre fini d'observations
indépendantes de cette dernière. Par exemple,
on pourrait s'imaginer observer un échantillon empirique issu d'une
loi normale de moyenne et de variance inconnue avec pour but
l'identification de ces paramètres inconnus.
Ainsi par exemple la loi des grands nombres justifierait
l'estimation d'une espérance mathématique par la moyenne
empirique, et on comprend qu'intuitivement que plus la taille de
l'échantillon est importante, meilleure sera l'estimation. La
théorie de la statistique inférentielle permet en particulier
d'évaluer de manière probabiliste la qualité de ce type
d'identifications. Cette section en donne quelques illustrations
sommaires avec l'aide de R.
Estimation ponctuelle
Nous savons que le ou les paramètres d'une loi de probabilité
résument de manière théorique certains aspects de cette
dernière. Les paramètres les plus habituels sont l'espérance
mathématique, notée ![]() , la variance
, la variance ![]() ,
une proportion
,
une proportion ![]() , une médiane
, une médiane ![]() , des quantiles, etc.
Ce ou ces paramètres, génériquement notés
, des quantiles, etc.
Ce ou ces paramètres, génériquement notés
![]() sont en général inconnus et
devront en général être approchés de manière optimale par
des statistiques
sont en général inconnus et
devront en général être approchés de manière optimale par
des statistiques
![]() calculées sur des échantillons
aléatoires issus de la loi (ou population) étudiée.
En pratique, la statistique calculée dépend de l'échantillon
tiré et produira une estimation variable du paramètre
inconnu. Ainsi par exemple si le paramètre inconnu
est l'espérance
calculées sur des échantillons
aléatoires issus de la loi (ou population) étudiée.
En pratique, la statistique calculée dépend de l'échantillon
tiré et produira une estimation variable du paramètre
inconnu. Ainsi par exemple si le paramètre inconnu
est l'espérance ![]() , la moyenne empirique d'un échantillon
, la moyenne empirique d'un échantillon
![]() issu de la loi est la variable aléatoire moyenne
empirique
issu de la loi est la variable aléatoire moyenne
empirique
![]() elle même
distribuée selon une certaine loi de probabilité. Il est
important de se souvenir que l'on ne réalise un échantillon qu'une
seule fois et donc que l'on ne dispose que d'une seule valeur de
l'estimateur
elle même
distribuée selon une certaine loi de probabilité. Il est
important de se souvenir que l'on ne réalise un échantillon qu'une
seule fois et donc que l'on ne dispose que d'une seule valeur de
l'estimateur
![]() (estimation ponctuelle).
(estimation ponctuelle).
La loi forte des grands nombres permet d'affirmer que pour une loi
admettant une espérance ![]() et une variance
et une variance ![]() , la moyenne
empirique
, la moyenne
empirique ![]() converge vers
converge vers ![]() alors que le théorème de
la limite centrale dit que la loi de la moyenne empirique
alors que le théorème de
la limite centrale dit que la loi de la moyenne empirique ![]() peut être approchée de mieux en mieux quand la taille de
l'échantillon tend vers l'infini par une loi normale d'espérance
peut être approchée de mieux en mieux quand la taille de
l'échantillon tend vers l'infini par une loi normale d'espérance
![]() et de variance
et de variance
![]() . On peut illustrer ces
propriétés par des expériences aléatoires appropriés,
programmées
avec R de la manière suivante.
. On peut illustrer ces
propriétés par des expériences aléatoires appropriés,
programmées
avec R de la manière suivante.
Pour un échantillon de la loi uniforme sur
![]() de taille
de taille ![]() , calculons les moyennes
empiriques successives et traçons la moyenne
empirique en fonction de la taille de l'échantillon. On
observe que la moyenne empirique converge bien vers la valeur
, calculons les moyennes
empiriques successives et traçons la moyenne
empirique en fonction de la taille de l'échantillon. On
observe que la moyenne empirique converge bien vers la valeur
![]() représentée par une droite horizontale rouge sur le
graphique 17.
représentée par une droite horizontale rouge sur le
graphique 17.
n<-1000 X<-runif(n) Y<-cumsum(X) N<-seq(1,n, by=1) plot(N, Y/N) abline(h=0.5,col="red")
Si l'on simule maintenant ![]() réalisations d'échantillons de
tailles respectives
réalisations d'échantillons de
tailles respectives ![]() et
et ![]() , issus d'une loi uniforme sur
, issus d'une loi uniforme sur
![]() on peut tracer sur un même graphique
l'histogramme des moyennes empiriques associées et illustrer
le fait que cet histogramme est proche de la densité de la loi normale de
moyenne
on peut tracer sur un même graphique
l'histogramme des moyennes empiriques associées et illustrer
le fait que cet histogramme est proche de la densité de la loi normale de
moyenne ![]() et de variance
et de variance
![]() avec
avec
![]() .
.
X<-matrix(runif(500*10), ncol=10, nrow=500) X1<-apply(X,1,mean) # 500 tirages de moyenne empirique Y<-matrix(runif(500*100), ncol=100, nrow=500) Y1<-apply(Y,1,mean) # 500 tirages de moyenne empirique par(mfrow=c(1,2)) hist(X1,main="Taille d'échantillon 10",prob=T) curve(dnorm(x,0.5,sqrt(1/120)),add=T) hist(Y1,main="Taille d'échantillon 100",prob=T) curve(dnorm(x,0.5,sqrt(1/1200)),add=T)
Intervalles de confiance et test d'hypothèses
Un domaine très important de la statistique inférentielle est la construction d'intervalles de confiance (estimation ensembliste) et la construction de tests d'hypothèses sur les paramètres des lois qui régissent les observations faites. Le logiciel R couvre l'essentiel des besoins en probabilités et statistiques élémentaires avec en particulier ceux utiles pour l'estimation par intervalles de confiance et des tests de base, ainsi que plusieurs outils d'ajustements graphiques de distributions. Nous allons en donner un aperçu dans les sous-paragraphes suivants.
Estimation ensembliste et tests d'une proportion
L'illustration la plus fréquente de la notion d'estimation
ensembliste est l'estimation par intervalle de confiance d'une
proportion inconnue ![]() au vu d'une réalisation d'un échantillon de loi de Bernoulli. Par
exemple, si lors d'un sondage d'une population vous observez la
réponse
de 100 personnes tirées au hasard dans la population et que vous
observez que 42 parmi elles aiment la marque X, que pouvez vous dire
de la probabilité
au vu d'une réalisation d'un échantillon de loi de Bernoulli. Par
exemple, si lors d'un sondage d'une population vous observez la
réponse
de 100 personnes tirées au hasard dans la population et que vous
observez que 42 parmi elles aiment la marque X, que pouvez vous dire
de la probabilité ![]() qu'une personne tirée au hasard dans la
population aime la marque X? Une première façon de répondre
à cette question
serait de proposer, comme dans les paragraphes précédents, une
estimation ponctuelle de cette probabilité
qu'une personne tirée au hasard dans la
population aime la marque X? Une première façon de répondre
à cette question
serait de proposer, comme dans les paragraphes précédents, une
estimation ponctuelle de cette probabilité ![]() , donc pour cet
exemple,
, donc pour cet
exemple,
![]() . Cette estimation dépend trop de la réponse du
sondage et pour une autre réalisation peut être différente. Il
serait donc opportun
de proposer plutôt une fourchette de valeurs pour
. Cette estimation dépend trop de la réponse du
sondage et pour une autre réalisation peut être différente. Il
serait donc opportun
de proposer plutôt une fourchette de valeurs pour ![]() qui tienne
compte de la variabilité de l'estimateur. Examinons cela de près :
notons
qui tienne
compte de la variabilité de l'estimateur. Examinons cela de près :
notons ![]() , ...,
, ..., ![]() les variables de Bernoulli
les variables de Bernoulli ![]() indépendantes modélisant la réponse éventuelle de chaque
individu parmi les
indépendantes modélisant la réponse éventuelle de chaque
individu parmi les
![]() tirés au hasard dans la population (dont l'effectif est très
grand). Nous avons vu que l'estimateur ponctuel de
tirés au hasard dans la population (dont l'effectif est très
grand). Nous avons vu que l'estimateur ponctuel de ![]() est la
moyenne empirique
est la
moyenne empirique
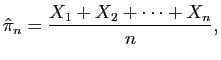
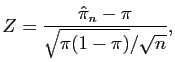
0.42 - qnorm(0.975)*sqrt(0.42*0.58)/sqrt{100}
0.42 + qnorm(0.975)*sqrt(0.42*0.58)/sqrt{100}
À titre d'exercice on pourra résoudre l'inégalité (1)
et se passer ainsi de l'utilisation de la loi des grands nombres pour
le calcul de l'intervalle de confiance.
Nous allons poursuivre cet exemple en illustrant par simulation le
fait qu'un intervalle de confiance ne recouvre pas toujours la vraie
valeur du paramètre ![]() . Ceci
ce réalise de manière simple avec la fonction
. Ceci
ce réalise de manière simple avec la fonction matplot et
les commandes suivantes, qui produisent la figure 19 :
m <- 50; n<-20; Pi <- .5; # 20 pièces à lancer 50 fois p <- rbinom(m,n,Pi)/n # simuler et calculer l'estimation ET<- sqrt(p*(1-p)/n) # estimer l'écart-type alpha = 0.10 # seuil de signification zstar <-qnorm(1-alpha/2) matplot(rbind(p-zstar*ET, p+zstar*ET),rbind(1:m,1:m),type="l",lty=1) abline(v=Pi) # trace la verticale en Pi
Bien évidemment la notion d'intervalle de confiance pour un
paramètre est la notion duale d'un test bilatéral
sur ce paramètre. Ainsi tester, au niveau de signification ![]() ,
que la vraie proportion est
,
que la vraie proportion est ![]() contre
son alternative
contre
son alternative
![]() au vu de la réalisation d'un
échantillon, équivaut à regarder si l'intervalle
de confiance pour
au vu de la réalisation d'un
échantillon, équivaut à regarder si l'intervalle
de confiance pour ![]() an niveau
an niveau
![]() recouvre ou non
recouvre ou non
![]() . Ainsi pour notre exemple du sondage
à propos de la marque X, ceci est réalisé avec la fonction
. Ainsi pour notre exemple du sondage
à propos de la marque X, ceci est réalisé avec la fonction
prop.test.
prop.test(42,100,conf.level=0.95)qui donne :
1-sample proportions test with continuity correction data: 42 out of 100, null probability 0.5 X-squared = 2.25, df = 1, p-value = 0.1336 alternative hypothesis: true p is not equal to 0.5 95 percent confidence interval: 0.3233236 0.5228954 sample estimates: p 0.42On notera les bornes de l'intervalle corrigées, qui différent légèrement de celles que nous avions déterminé avec la loi des grands nombres. Le résultat affiché est une liste, dont on peut extraire les composants. Par exemple pour l'intervalle de confiance :
prop.test(42,100,conf.level=0.95)$conf.int
Les tests et l'estimation par intervalle issus d'autres lois suivent la même configuration.
Estimation ensembliste et tests sur la moyenne
Considérons à titre d'exemple l'estimation ensembliste de la moyenne ![]() au niveau de confiance
au niveau de confiance
![]() au vu d'une réalisation d'un
échantillon gaussien
au vu d'une réalisation d'un
échantillon gaussien
![]() , ...,
, ..., ![]() d'espérance
d'espérance ![]() et de variance connue
et de variance connue
![]() . Nous savons
que l'intervalle de confiance pour
. Nous savons
que l'intervalle de confiance pour ![]() est de la forme
est de la forme
![]() .
On peut construire une fonction simple pour son calcul comme suit :
.
On peut construire une fonction simple pour son calcul comme suit :
ICsimple <-function(x,sigma,niv.conf=0.95){
n <- length(x)
xbar<-mean(x)
alpha <- 1-niv.conf
zstar <- qnorm(1-alpha/2)
ET <- sigma/sqrt(n)
xbar + c(-zstar*ET,zstar*ET)
}
qui donne, pour une réalisation x :
x<-c(175,176,173,175,174,173 ,173 ,176,173,179) ICsimple(x,1.5) [1] 173.7703 175.6297De manière plus réaliste, la variance est plutôt inconnue et l'intervalle de confiance est calculé à l'aide de la loi de Student. En effet, si
t.test() qui non seulement
calcule le test de l'hypothèse désirée sur t.test(x,alternative="two.sided", mu=170)
qui donne :
One Sample t-test
data: x
t = 7.6356, df = 9, p-value = 3.206e-05
alternative hypothesis: true mean is not equal to 170
95 percent confidence interval:
173.3076 176.0924
sample estimates:
mean of x
174.7
et rejette l'hypothèse nulle puisque la p-valeur est
t.test(x,alternative="less", mu=170)
donne :
One Sample t-test
data: x
t = 7.6356, df = 9, p-value = 1
alternative hypothesis: true mean is less than 170
95 percent confidence interval:
-Inf 175.8284
sample estimates:
mean of x
174.7
et accepte l'hypothèse
Test d'adéquation et d'indépendance
Pour terminer ce paragraphe, voici les tests
du chi-deux d'ajustement et de contingence.
Un test d'ajustement permet de décider
si la distribution des valeurs d'une échantillon est correctement ajustée
par une loi de probabilité spécifiée à l'avance. Par exemple,
si on lance
un dé 150 fois de manière indépendante et que l'on observe
les fréquences suivantes
| face | 1 | 2 | 3 | 4 | 5 | 6 |
| fréq. | 22 | 21 | 22 | 27 | 22 | 36 |
Pour cela il suffit d'évaluer la distance entre les fréquences observées et celles qui auraient dû être observées si le dé était bien équilibré. Cette distance est, dans le cas équilibré, distribuée selon une loi du chi deux à 5 degrés de liberté et est obtenue par :
freq <- c(22,21,22,27,22,36) probs <- c(1,1,1,1,1,1)/6 chisq.test(freq,p=probs)qui donne :
Chi-squared test for given probabilities
data: freq
X-squared = 6.72, df = 5, p-value = 0.2423
confortant ainsi l'hypothèse d'un dé bien équilibré.
La même fonction peut être également utilisée pour tester
l'indépendance des variables dans une table de contingence.
On suppose observer deux variables catégorielles ![]() et
et ![]() ,
respectivement à
,
respectivement à ![]() et
et ![]() modalités. On observe ainsi
indépendamment le couple
modalités. On observe ainsi
indépendamment le couple ![]() sur une population de
sur une population de ![]() sujets. Soit alors
sujets. Soit alors ![]() le nombre de sujets pour lesquels on a
le nombre de sujets pour lesquels on a
![]() , de sorte que
, de sorte que
![]() . Les comptages observés peuvent être organisés en un tableau
à double entrée :
. Les comptages observés peuvent être organisés en un tableau
à double entrée :
À titre d'exemple considérons, dans une étude d'accidents de
voiture, les variables ![]() (port de ceinture, oui ou non ) et
(port de ceinture, oui ou non ) et ![]() (gravité de la blessure, aucune, minimale,
légère, grave) avec pour tableau observé :
(gravité de la blessure, aucune, minimale,
légère, grave) avec pour tableau observé :
| aucune | minimale | légère | grave | ||
| Ceinture | Oui | 128213 | 647 | 359 | 42 |
| Non | 65963 | 4000 | 2642 | 303 |
avecceinture<-c(12813,647,359,42) sansceinture<- c(65963,4000,2642,303) chisq.test(data.frame(avecceinture,sansceinture))qui donne
Pearson's Chi-squared test data: data.frame(avecceinture, sansceinture) X-squared = 59.224, df = 3, p-value = 8.61e-13et montre l'influence évidente du port de la ceinture.
Régression linéaire simpleDans ce paragraphe nous allons examiner une modélisation
particulière pour étudier (décrire, prédire, ...) une
variable appelée variable expliquée (ou réponse ou
variable dépendante) sur la base d'autres variables,
appelées explicatives (ou covariables ou
variables indépendantes). Nous nous resteindrons au cas d'une
seule variable explicative d'où la notion de régression
simple.
Un modèle de régression linéaire simple décrit le cas
particulier d'une seule variable explicative ![]() de type quantitatif
(aléatoire ou déterministe) pour un phénomène physique régi
par l'équation
de type quantitatif
(aléatoire ou déterministe) pour un phénomène physique régi
par l'équation
Considérons d'abord l'exemple d'une régression linéaire simple
pour laquelle la droite de régression est donnée par l'équation
![]() . Cette droite est représentée
par la droite de couleur bleue dans le graphique de gauche de la
figure 20. Les observations se font en des points
. Cette droite est représentée
par la droite de couleur bleue dans le graphique de gauche de la
figure 20. Les observations se font en des points ![]() fixés, données par les abscisses
fixés, données par les abscisses
![]() ,
,
![]() des points rouges, d'ordonnées
des points rouges, d'ordonnées
![]() situés sur la
droite. En chaque point
situés sur la
droite. En chaque point ![]() on tire au hasard, 5 observations selon
une loi gaussienne
de moyenne
on tire au hasard, 5 observations selon
une loi gaussienne
de moyenne ![]() et de variance
et de variance ![]() , représentées par les points
bleus sur le graphique du centre. En réalité, l'ensemble des
données observées pour cet exemple simulé
est le nuage des points du dernier graphique. La fonction permettant
de tracer des densités gaussiennes à la verticale est :
, représentées par les points
bleus sur le graphique du centre. En réalité, l'ensemble des
données observées pour cet exemple simulé
est le nuage des points du dernier graphique. La fonction permettant
de tracer des densités gaussiennes à la verticale est :
sideways.dnorm<-function(wx,wy,values=seq(-4,4,.1),magnify=4,...){
# ... est constitué des moyennes et écart-types,
# passés à la fonction dnorm
#
dens <- dnorm(x=values, ...)
x <- wx + dens * magnify
y <- wy + values
return(cbind(x,y))
}
et les graphiques de la figure 20 sont réalisés avec
les commandes :
par(mfrow=c(1,3))
x<-seq(-8,8,2)
y <- 1 + .5*x
fit <- lm(y~x)
plot(x,y, xlim=c(-10,10), ylim=c(-3, 7), pch=19,
cex=1.4,col="red", main="équation de régression")
abline(fit, lwd=3, col="blue")
plot(x,y, xlim=c(-10,10), ylim=c(-8, 10), pch=19, cex=1.4
, main="Régression linéaire simple\navec erreurs gaussiennes"
, col="red")
abline(fit, lwd=3, col="blue")
where.normal.x<-sort(x)
xx<-NULL
zz<-NULL
# where.normal.x <- c(-4,0,4)
for(i in 1:length(where.normal.x)){
where.x <- where.normal.x[i]
where.y <- predict(fit, newdata=data.frame(x=where.x))
xy <- sideways.dnorm(where.x=where.x, where.y=where.y, magnify=4)
lines(xy)
abline(h=where.y, lty=2,col="pink")
abline(v=where.x, lty=2)
xx<-c(xx,rep(where.x,5))
z<-where.y+rnorm(5)
zz<-c(zz,z)
aux<-cbind(rep(where.x,5),z)
points(aux,col="blue")
}
plot(xx,zz,xlim=c(-10,10), ylim=c(-3, 7),main="les observations")
Pour continuer avec ce modèle simulé de régression linéaire
simple, on voudrait à partir des ![]() observations
observations
![]() estimer les coefficients
estimer les coefficients ![]() et
et ![]() de la droite modélisant
les
de la droite modélisant
les ![]() comme des réalisations de variables
aléatoires
comme des réalisations de variables
aléatoires ![]() , non corrélées, de moyennes
, non corrélées, de moyennes ![]() et de
variance constante
et de
variance constante ![]() . Pour cela on utilise le principe des
moindres carrés
qui consiste à minimiser la fonction de perte :
. Pour cela on utilise le principe des
moindres carrés
qui consiste à minimiser la fonction de perte :
![$\displaystyle \ell_2(a,b) = \sum_{i=1}^n[ y_i - (ax_i+b) ]^2,$](img166.gif)
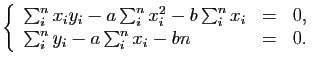 |
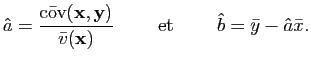
La dernière équation montre que la droite des moindres carrés
passe par le centre
de gravité du nuage
![]() . On pouvait
s'attendre à ce résultat car la meilleure prédiction de
. On pouvait
s'attendre à ce résultat car la meilleure prédiction de ![]() lorsque
lorsque ![]() doit bien être
doit bien être ![]() .
.
Pour ce cas particulier l'estimation sans biais de la variance
![]() est donnée par
est donnée par
![$\displaystyle \hat{\sigma}^2 = \frac{1}{n-2}\sum_{i=1}^n[ y_i - (\hat{a}x_i+\hat{b}) ]^2.$](img179.gif)
Pour l'exemple des données simulées, l'ajustement des moindres
carrés s'obtient avec la commande lm()
et on obtient la figure 21 avec les commandes
{plot(xx,zz,xlim=c(-10,10), ylim=c(-3, 7),
main="Ajustement des moindres carrés")}
fitb<-lm(zz~xx)
abline(fitb,lty=2,col="blue",lwd=3)
abline(fit,lty=1,col="black")
![\includegraphics[width=10cm]{reglin2}](img180.gif)
|
Les sorties R associées à un ajustement d'un jeu de données par
un modèle de régression linéaire à l'aide de la fonction
lm()
peut s'obtenir par un summary() de l'objet ajusté.
fitb<-lm(zz~xx) summary(fitb)qui donne
Call:
lm(formula = zz ~ xx)
Residuals:
Min 1Q Median 3Q Max
-1.94795 -0.62929 -0.08101 0.43664 2.36308
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.86451 0.14747 5.862 5.79e-07 ***
xx 0.50503 0.02856 17.685 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9892 on 43 degrees of freedom
Multiple R-squared: 0.8791, Adjusted R-squared: 0.8763
F-statistic: 312.8 on 1 and 43 DF, p-value: < 2.2e-16
On y retrouve une description par quantiles de la distribution des
valeurs de la réponse (ici zz)
puis les estimations ponctuelles de l'ordonnée à l'origine et de la
pente, avec l'estimation de leurs
écart-types et des p-valeurs des tests de nullité de chacun des
paramètres (qui ne tiennent pas compte
de leur corrélation). Enfin, l'estimation ponctuelle de
l'écart-type est donnée sur la ligne suivant le tableau
des coefficients. On y retrouve aussi les valeurs estimées du
coefficient de détermination et la p-valeur du test d'absence
d'influence du régresseur. Comme d'habitude, le résultat est une
liste dont on peut extraire les composants. Par exemple pour
l'ordonnée à l'origine, puis la pente :
fitb$coefficients[1] fitb$coefficients[2]
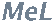 © UJF Grenoble, 2011
Mentions légales
© UJF Grenoble, 2011
Mentions légales
![\includegraphics[width=7cm]{dens1}](img63.gif)
![\includegraphics[width=6cm]{dens2}](img66.gif)
![\includegraphics[width=6cm]{dens3}](img68.gif)
![\includegraphics[width=6cm]{dens4}](img69.gif)
![\includegraphics[width=6cm]{lng}](img82.gif)
![\includegraphics[width=6cm]{clt}](img87.gif)
![% latex2html id marker 7645
\includegraphics[width=6cm]{ICprop}](img105.gif)
![\includegraphics[width=15cm]{reglin1}](img160.gif)